.jpg?table=collection&id=15559529-ab3e-812c-8768-000b937dad10&t=15559529-ab3e-812c-8768-000b937dad10&width=800&cache=v2)

type
status
date
slug
summary
tags
category
icon
password
本 wiki 指南介绍了如何将 YOLOv8 模型部署到 NVIDIA Jetson 平台并使用 TensorRT 执行推理。这里我们使用 TensorRT 来最大化 Jetson 平台上的推理性能。
这里将介绍不同的计算机视觉任务,例如:
- 物体检测
- 图像分割
- 图像分类
- 姿势估计
- 物体追踪

先决条件
- Ubuntu 主机 PC(本机或使用 VMware Workstation Player 的虚拟机)
- reComputer Jetson
或任何其他运行 JetPack 5.1.1 或更高版本的 NVIDIA Jetson 设备
笔记
本 wiki 已在由 NVIDIA Jetson orin NX 16GB 模块提供支持的reComputer J4012和 reComputer Industrial J4012 [https://www.seeedstudio.com/reComputer-Industrial-J4012-p-5684.html]上进行了测试和验证
将 JetPack 闪存到Jetson
现在您需要确保 Jetson 设备已安装JetPack系统。您可以使用 NVIDIA SDK Manager 或命令行将 JetPack 刷新到设备。
有关 Seeed Jetson 驱动的设备刷机指南,请参考以下链接:
笔记
确保 Flash JetPack 版本为 5.1.1,因为这是我们为此 wiki 验证的版本
只需一行代码即可将YOLOV8部署到Jetson !
使用 JetPack 刷新 Jetson 设备后,您只需运行以下命令即可运行 YOLOv8 模型。这将首先下载并安装必要的包、依赖项、设置环境并从 YOLOv8 下载预训练模型来执行对象检测、图像分割、姿势估计和图像分类任务!
笔记
使用预先训练的模型
开始使用 YOLOv8 的最快方法是使用 YOLOv8 提供的预训练模型。然而,这些是 PyTorch 模型,因此只会在 Jetson 上进行推理时使用 CPU。如果您希望这些模型在 GPU 上运行时在 Jetson 上获得最佳性能,您可以按照 wiki 的这一部分将 PyTorch 模型导出到 TensorRT。
- 物体检测
- 图像分类
- 图像分割
- 姿势估计
- 物体追踪
YOLOv8 提供 5 个预训练的 PyTorch 模型权重用于对象检测,在输入图像大小为 640x640 的 COCO 数据集上进行训练。您可以在下面找到它们
模型 | 尺寸(像素) | MAP值50-95 | CPU ONNX速度(毫秒) | A100 TensorRT速度(毫秒) | 参数(M) | 失败次数(B) |
640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 | |
640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 | |
640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 | |
640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 | |
640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
参考: https: //docs.ultralytics.com/tasks/detect
您可以从上表中选择并下载所需的模型,然后执行以下命令对图像进行推理
这里的模型,您可以更改为yolov8s.pt、yolov8m.pt、yolov8l.pt、yolov8x.pt,它将下载相关的预训练模型
您还可以连接网络摄像头并执行以下命令
笔记
如果执行上述命令时遇到任何错误,请尝试在命令末尾添加“device=0”

笔记
上述代码在 reComputer J4012/reComputer Industrial J4012 上运行,并使用 YOLOv8s 模型(通过 640x640 输入进行训练)并使用 TensorRT FP16 精度。
使用 TensorRT 提高推理速度
正如我们之前提到的,如果要提高运行YOLOv8模型的Jetson上的推理速度,首先需要将原始PyTorch模型转换为TensorRT模型。
按照以下步骤将 YOLOv8 PyTorch 模型转换为 TensorRT 模型。
笔记
这适用于我们之前提到的所有四个计算机视觉任务
- 步骤1.
通过指定模型路径执行导出命令
例如:
笔记
如果您遇到有关 cmake 的错误,可以忽略它。请耐心等待 TensorRT 导出完成。可能需要几分钟
创建 TensorRT 模型文件(.engine)后,您将看到如下输出
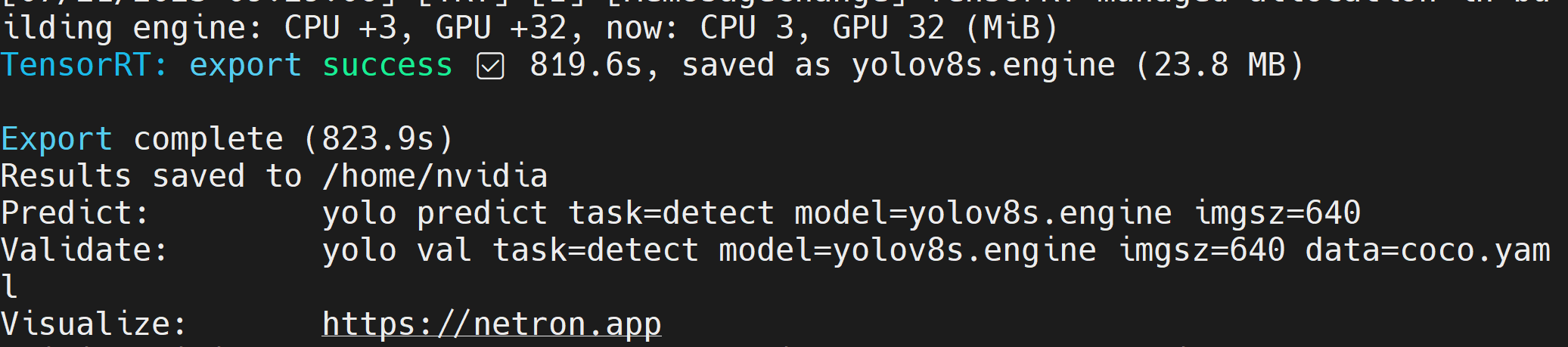
- 步骤 2.
如果您想传递其他参数,可以按照下表进行操作
钥匙 | 价值 | 描述 |
伊姆格斯兹 | 640 | 图像大小为标量或 (h, w) 列表,即 (640, 480) |
一半 | 错误的 | FP16 量化 |
动态的 | 错误的 | 动态轴 |
简化 | 错误的 | 简化模型 |
工作空间 | 4 | 工作空间大小 (GB) |
例如,如果要将 PyTorch 模型转换为 FP16 量化的 TensorRT 模型,请执行为
模型导出成功后,在运行检测、分类、分割、姿态估计这4个任务时,可以直接用yolo的predict命令中的model=参数替换该模型。
例如,对于物体检测:
带来您自己的人工智能模型
数据收集和标签
如果您有特定的 AI 应用程序,并且希望引入适合您的应用程序的自己的 AI 模型,您可以收集自己的数据集,对其进行标记,然后使用 YOLOv8 进行训练。
如果您不想自己收集数据,也可以选择现成的公共数据集。您可以下载许多公开可用的数据集,例如COCO 数据集、Pascal VOC 数据集等等。Roboflow Universe是一个推荐的平台,它提供了广泛的数据集,它拥有90,000 多个数据集,其中有 66+ 百万张图像可用于构建计算机视觉模型。此外,您还可以简单地在 Google 上搜索开源数据集,并从各种可用数据集中进行选择。
培训
这里我们有 3 种方法来训练模型。
- 第一种方法是使用Ultralytics HUB。您可以轻松地将 Roboflow 集成到 Ultralytics HUB 中,以便您的所有 Roboflow 项目都可以随时用于培训。这里它提供了一个 Google Colab 笔记本,可以轻松开始训练过程,还可以实时查看训练进度。
- 第二种方法是使用我们创建的 Google Colab 工作区来简化训练过程。这里我们使用 Roboflow API 从 Roboflow 项目下载数据集。
- 第三种方法是使用本地 PC 进行培训过程。这里需要确保你有足够强大的GPU,并且还需要手动下载数据集。
- Ultralytics HUB + Roboflow + Google Colab
- Roboflow + 谷歌 Colab
- Roboflow + 本地 PC
这里我们使用Ultralytics HUB加载Roboflow项目,然后在Google Colab上进行训练。
- 步骤 1.访问此 URL并注册 Ultralytics 帐户
- 步骤 2.使用新创建的帐户登录后,您将看到以下仪表板
- 步骤 3.访问此 URL并注册 Roboflow 帐户
- 步骤 4.使用新创建的帐户登录后,您将看到以下仪表板
- 步骤5.创建一个新的工作区,并按照我们准备的wiki指南在工作区下创建一个新项目。您还可以在此处查看Roboflow 官方文档以了解更多信息。
- 步骤 6.一旦您的工作区中有几个项目,它将如下所示
- 步骤 7.“设置”Roboflow API
转到
并单击
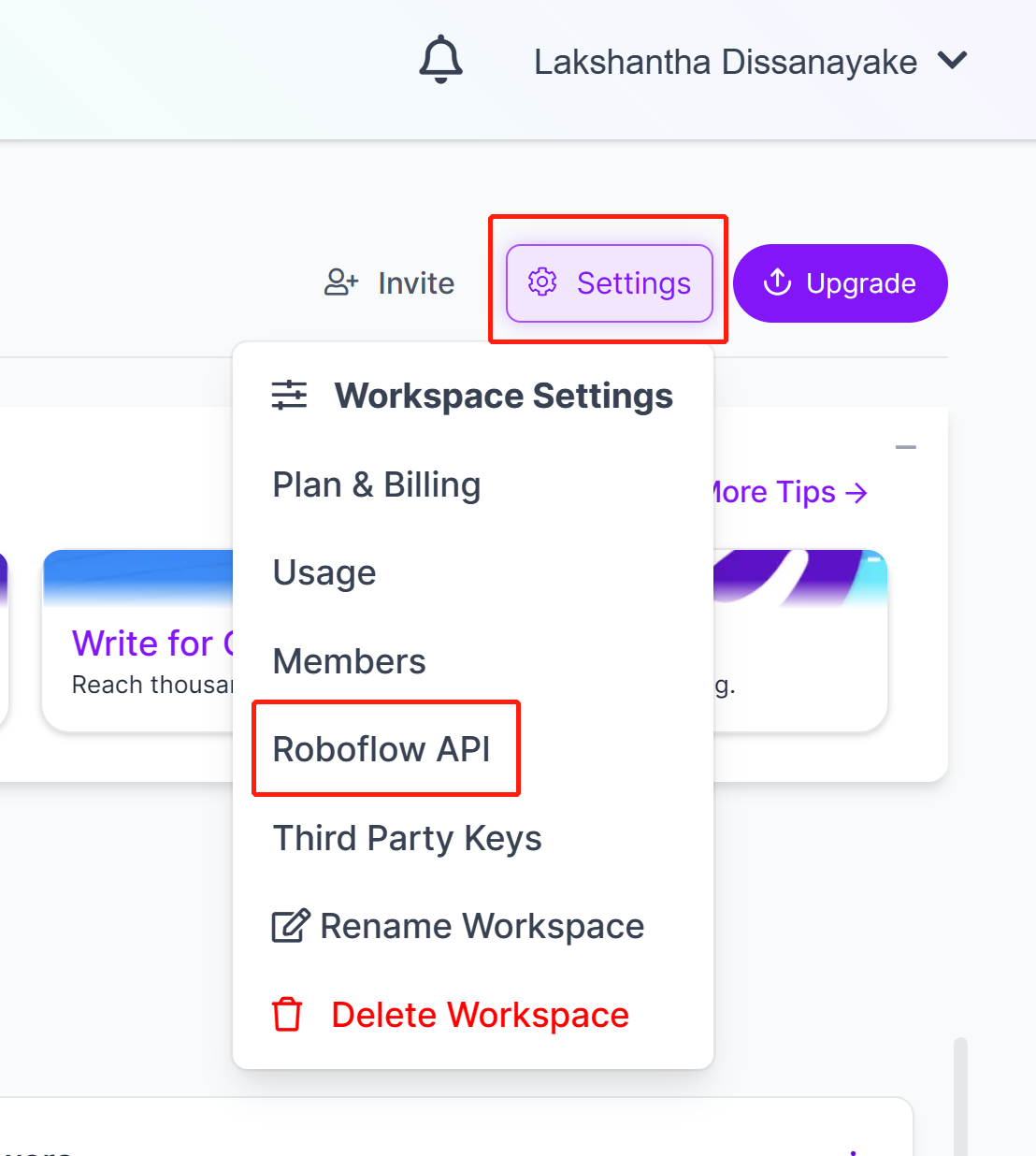
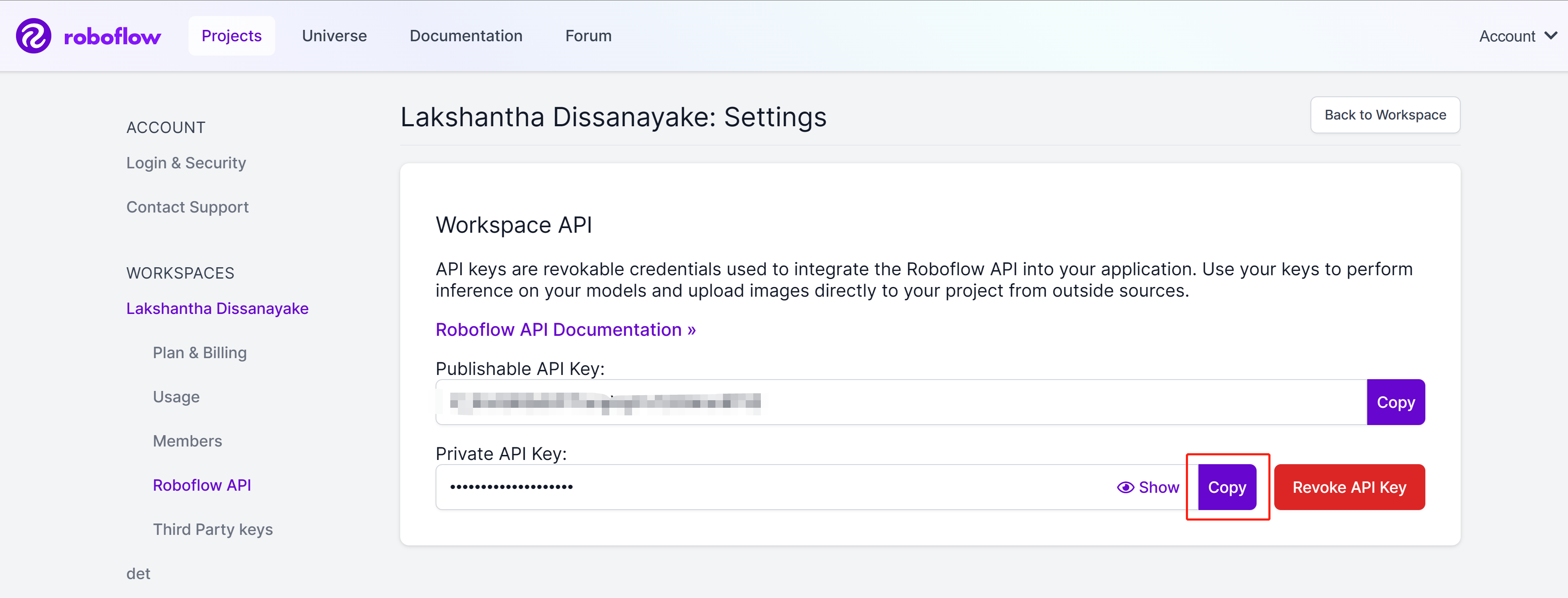
- 步骤 8.复制Private API Key
单击
按钮复制
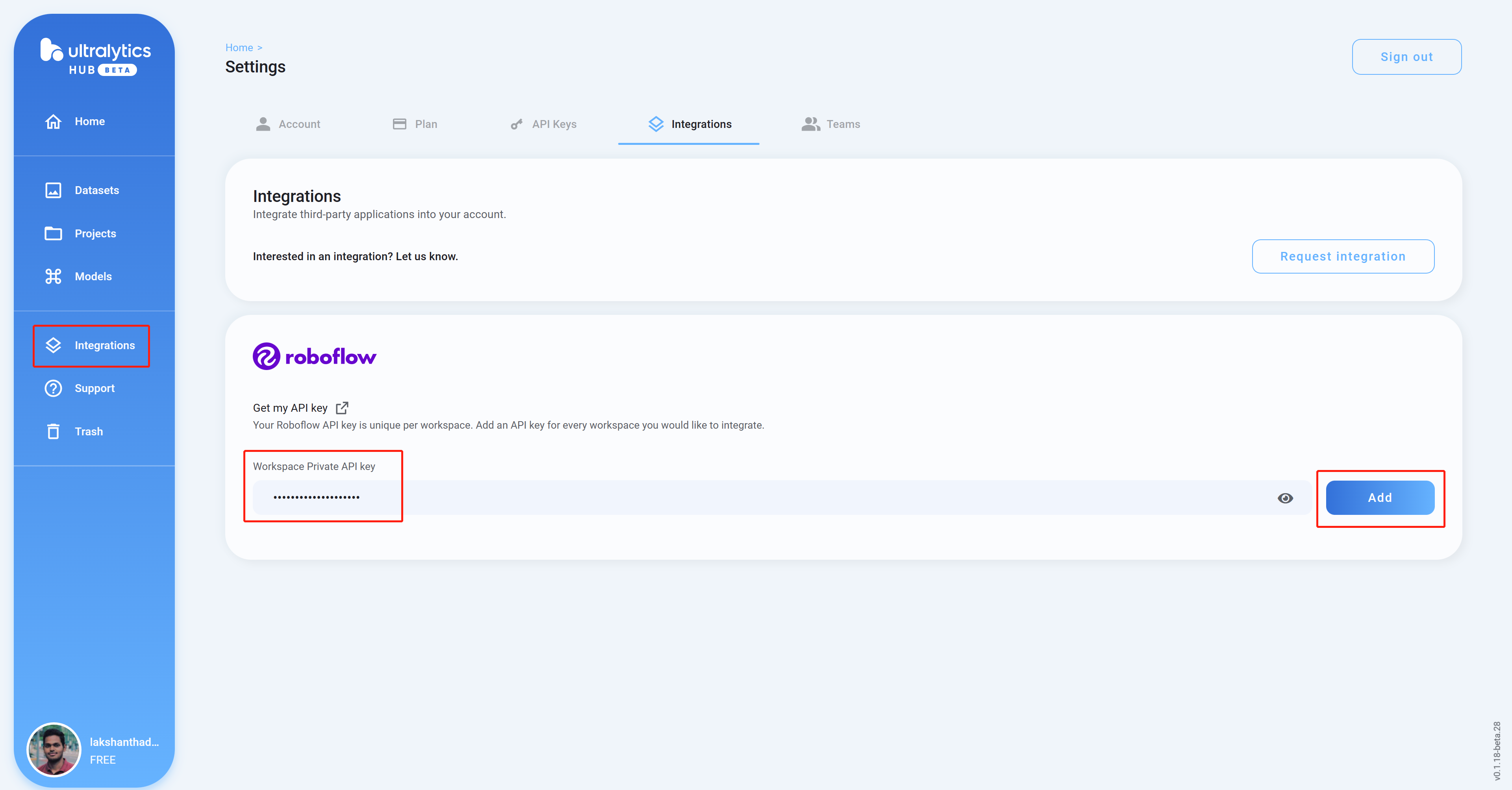
- 步骤9.“集成”“添加”
返回Ultralytics HUB仪表板,单击
,将我们之前复制的API密钥粘贴到空列中,然后单击
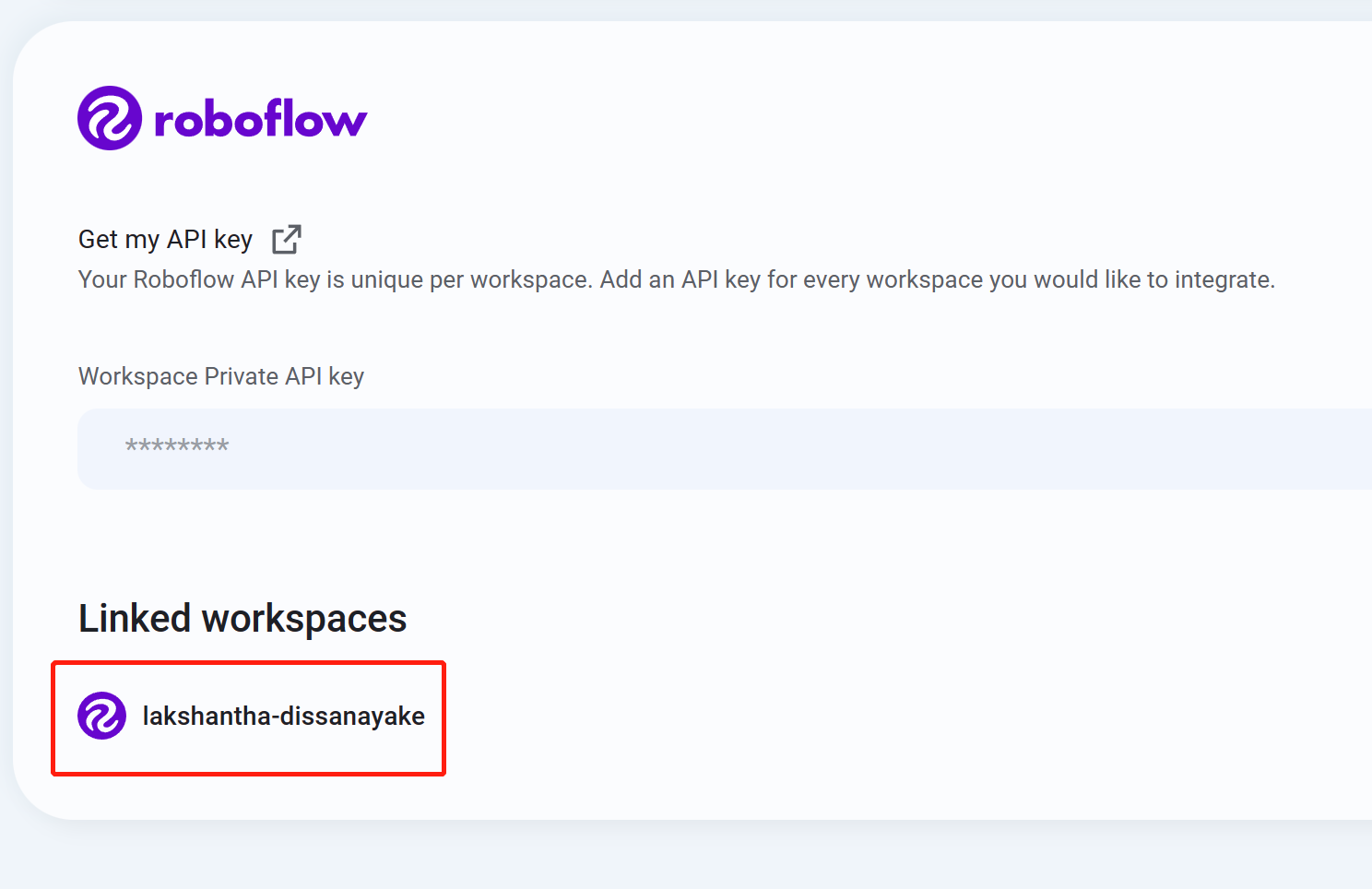
- 步骤 10
如果看到列出了您的工作区名称,则表示集成成功
- 步骤 11数据集
导航到
,您将在此处看到所有 Roboflow 项目
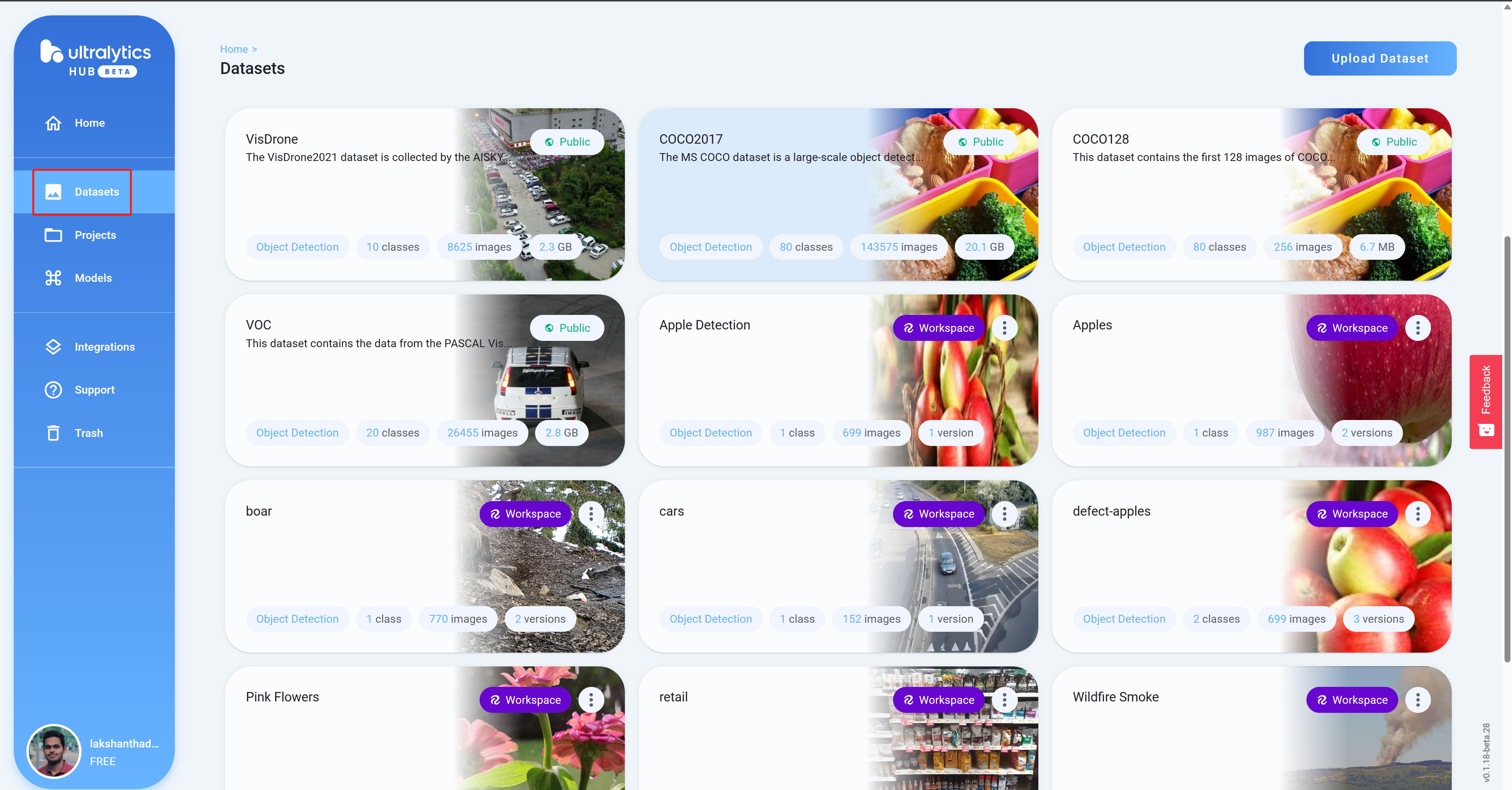
- 步骤 12
单击项目以查看有关数据集的更多信息。这里我选择了一个可以检测健康和受损苹果的数据集
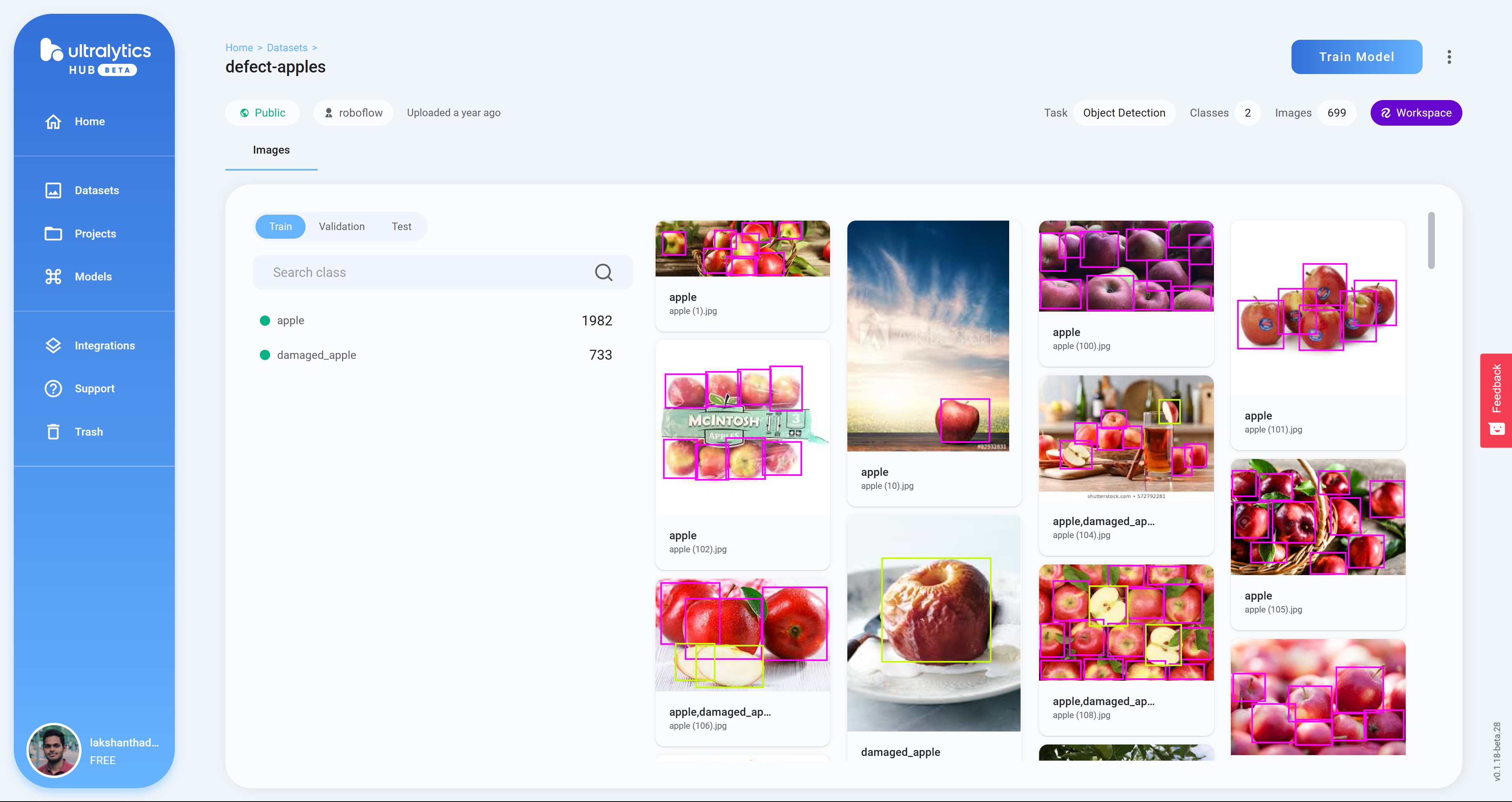
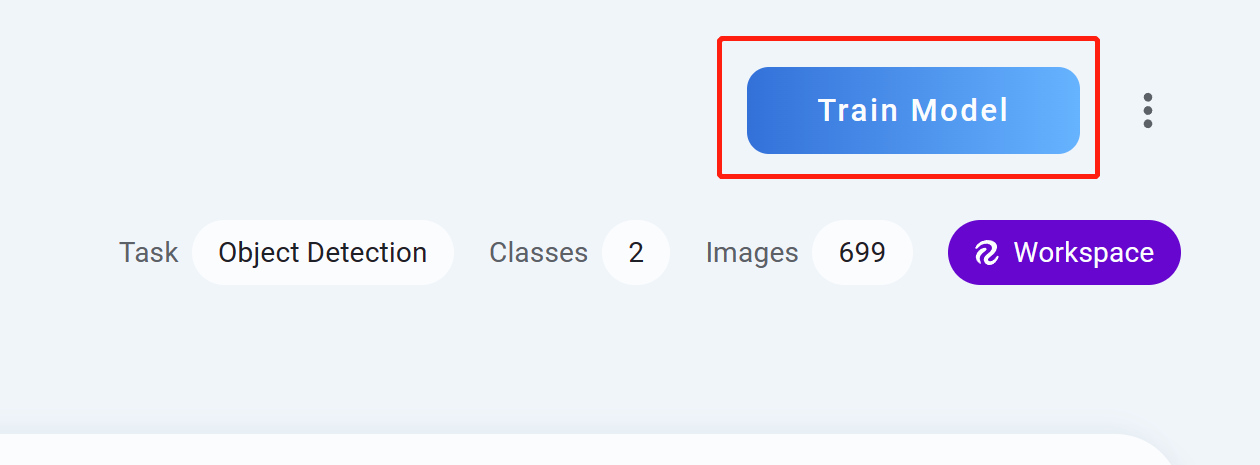
- 步骤 13训练模型
单击
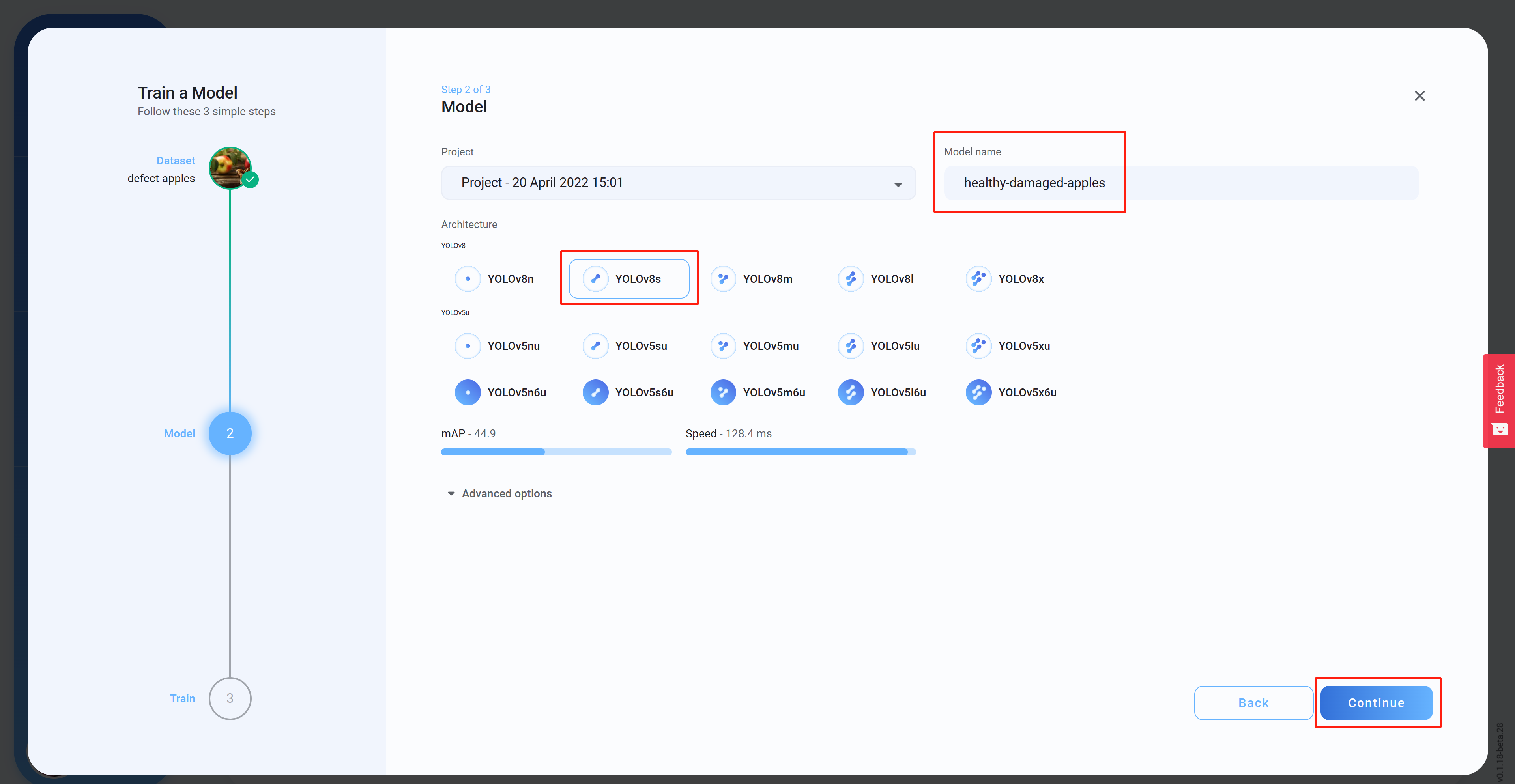
- 步骤 14架构模型名称(可选)继续
选择
,设置
,然后单击
。这里我们选择YOLOv8s作为模型架构
- 步骤 15“高级选项”打开 Google Colab”
在
下,根据您的偏好配置设置,复制并粘贴 Colab 代码(这将稍后粘贴到 Colab 工作区中),然后单击“
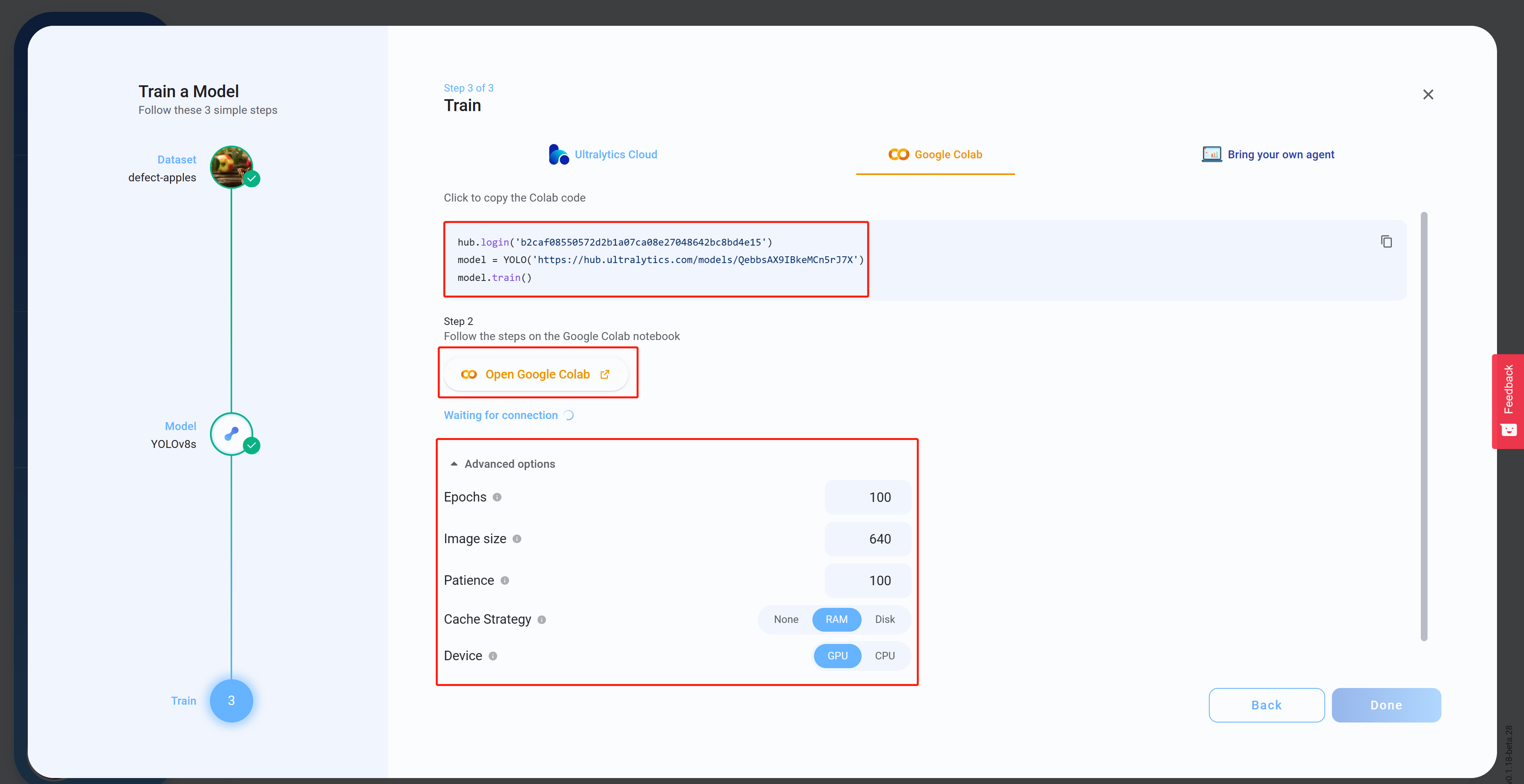
- 步骤 16
如果您尚未登录,请登录您的 Google 帐户
- 步骤 17
Runtime > Change runtime type
导航至
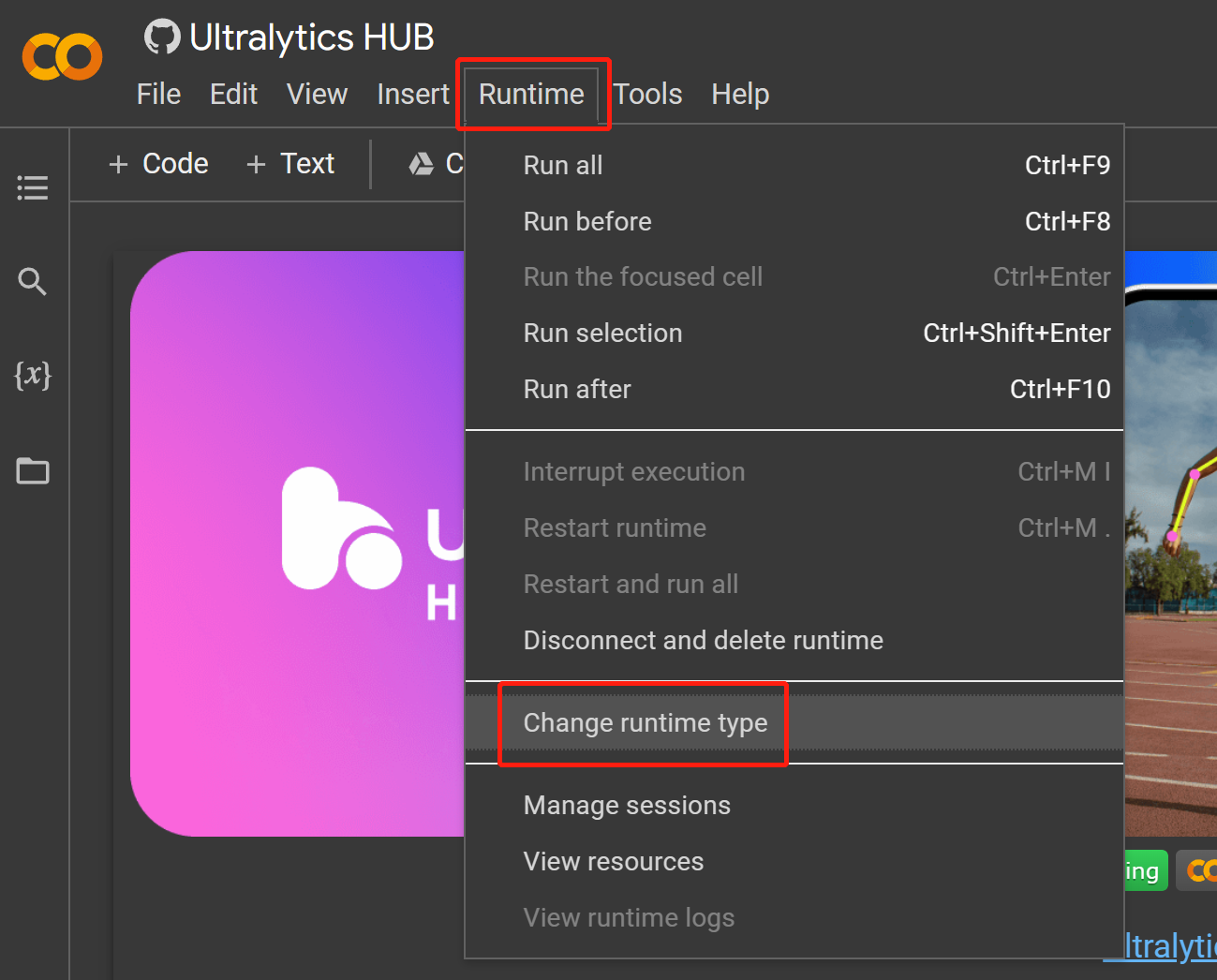
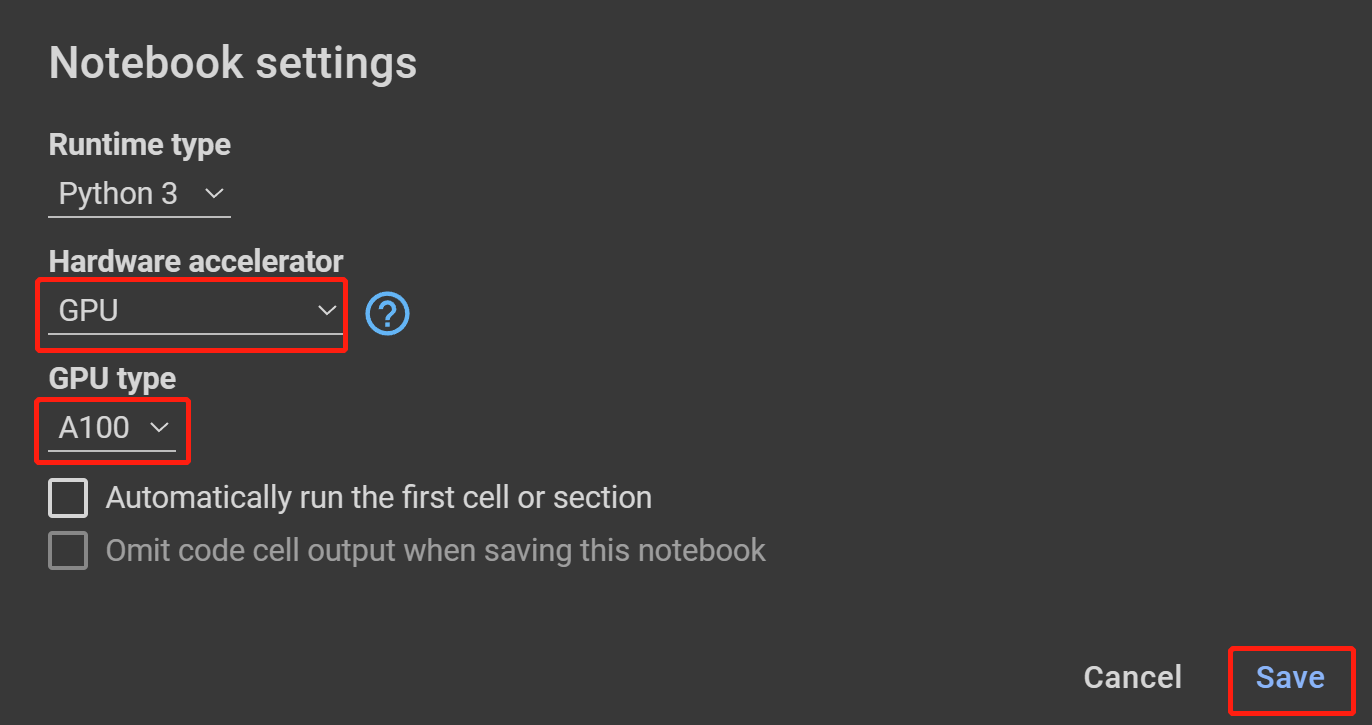
- 步骤 18GPU ,在
在硬件加速器下选择
GPU 类型下选择最高可用的,然后单击保存
- 步骤 19“连接”
单击
- 步骤20RAM、Disk
点击
按钮查看硬件资源使用情况
- 步骤 21“播放”
单击
按钮运行第一个代码单元
- 步骤 22“开始”
将我们之前从 Ultralytics HUB 复制的代码单元粘贴到
部分下并运行它以开始训练
- 步骤 23Connected“完成”
现在,如果您返回 Ultralytics HUB,您将看到消息
。单击
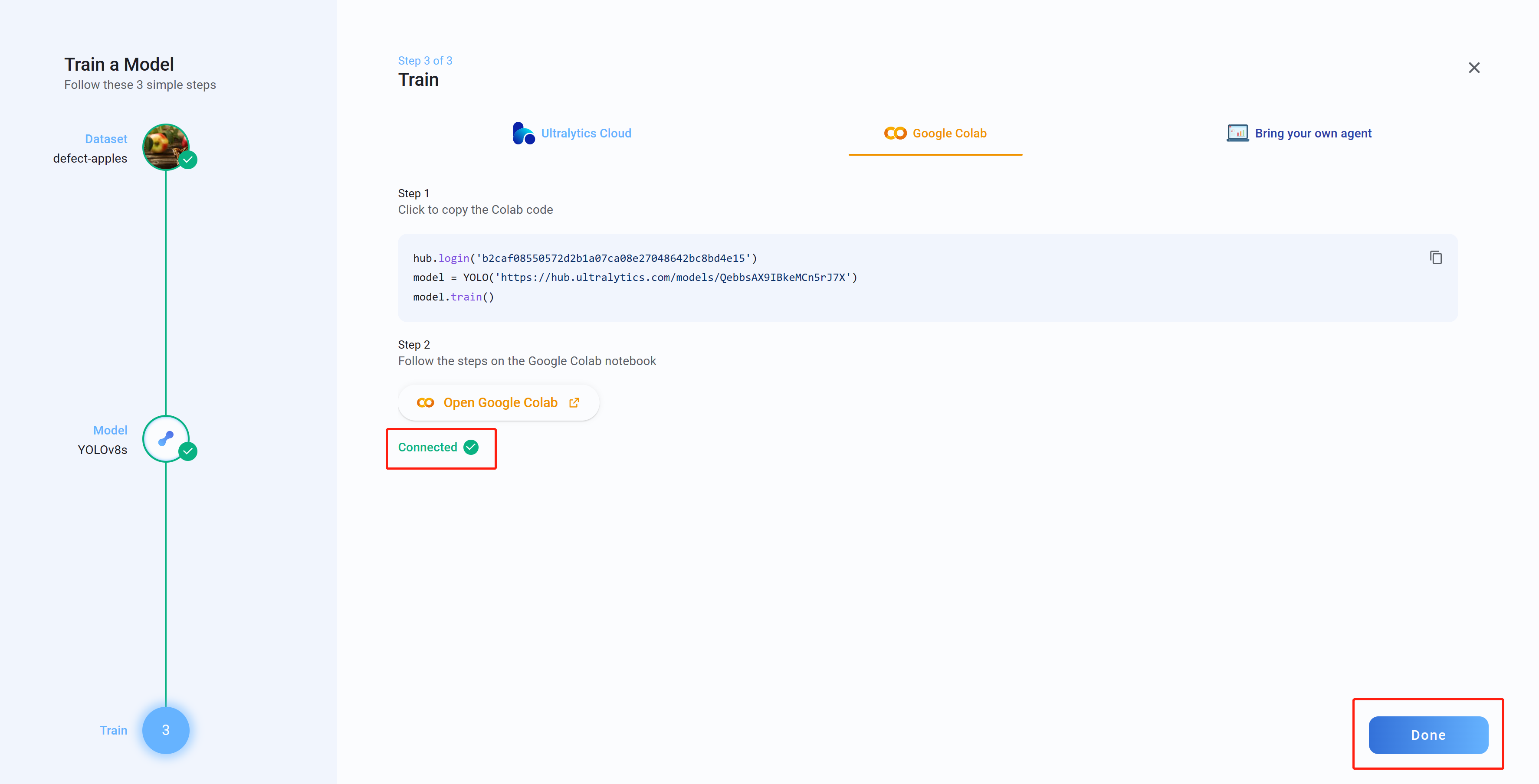
- 步骤 24Box Loss、Class Loss 和 Object Loss
在这里,当模型在 Google Colab 上训练时,您将实时看到
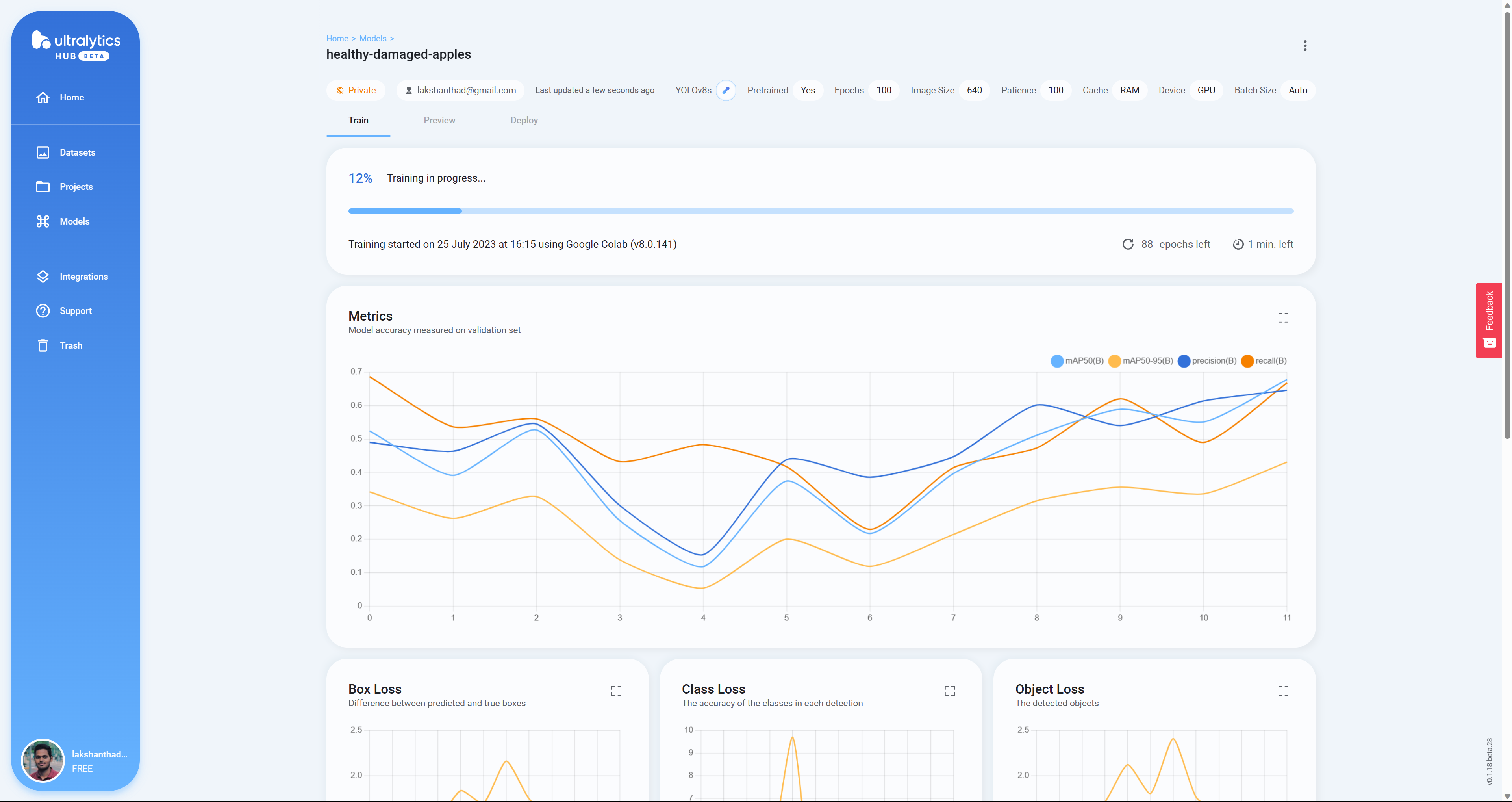
- 步骤25
训练完成后,您将在Google Colab上看到以下输出
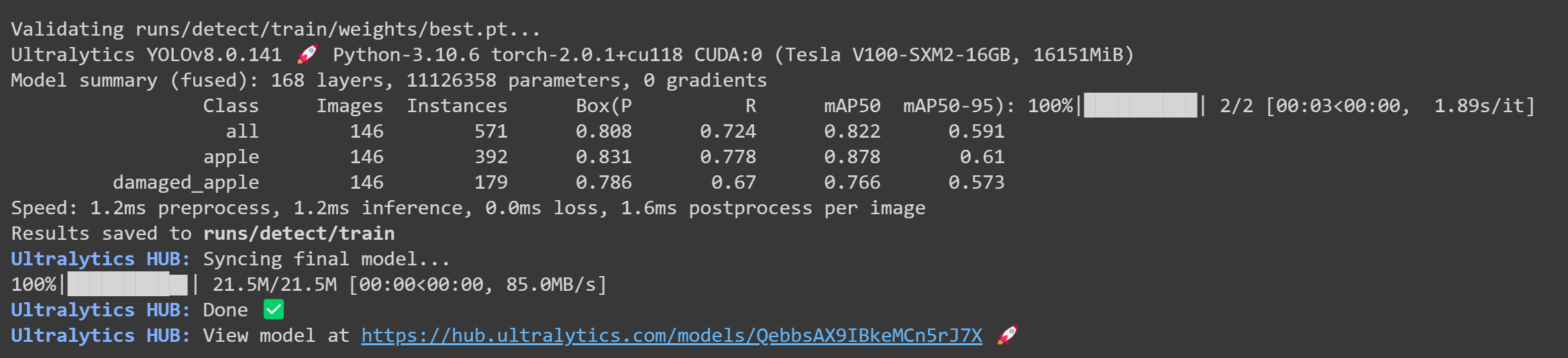
- 步骤 26“预览”
现在返回 Ultralytics HUB,转到
选项卡并上传测试图像以检查训练后的模型的表现
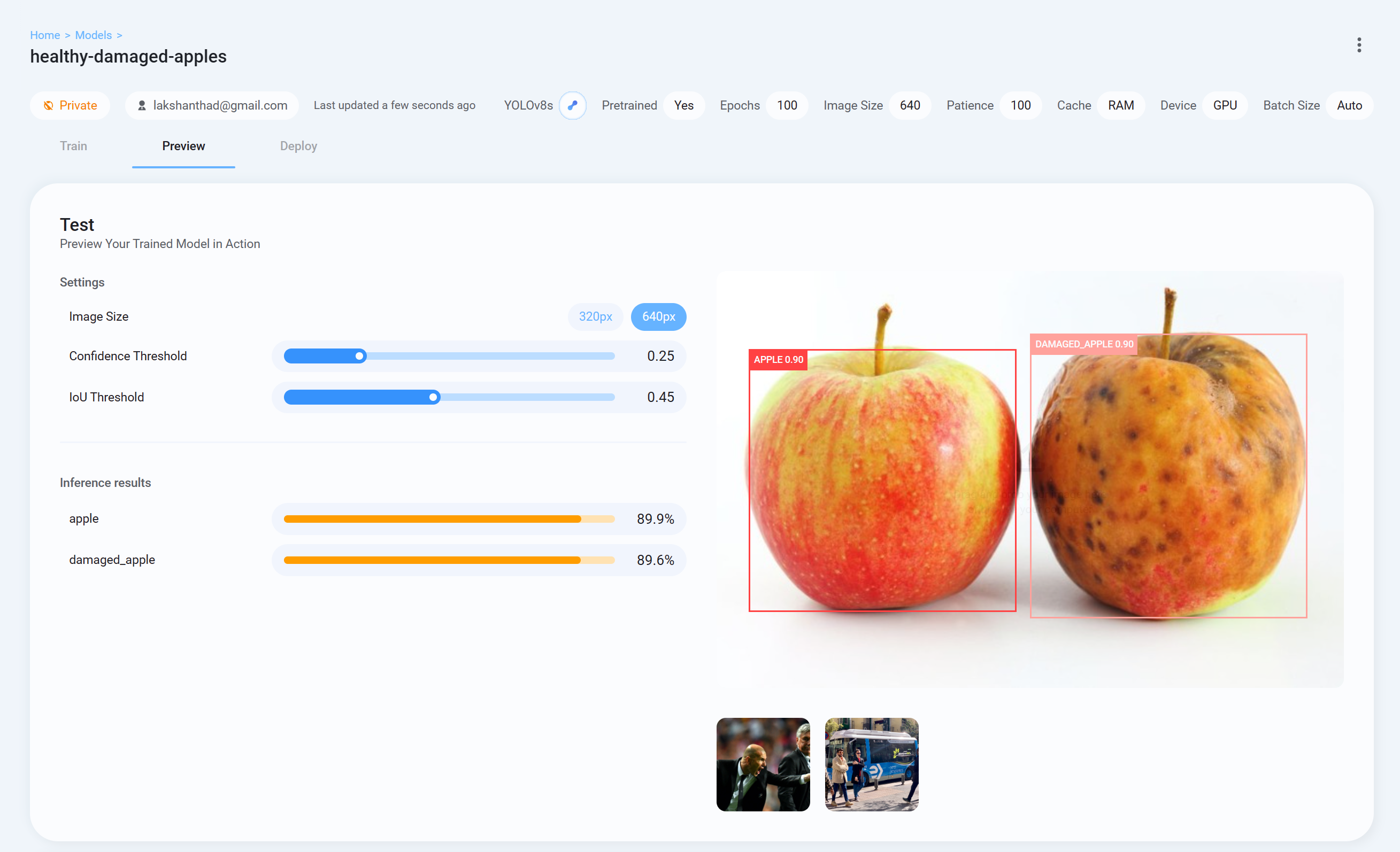
- 步骤 26“部署”
最后转到
选项卡,并以您喜欢使用 YOLOv8 进行推理的格式下载经过训练的模型。这里我们选择PyTorch。
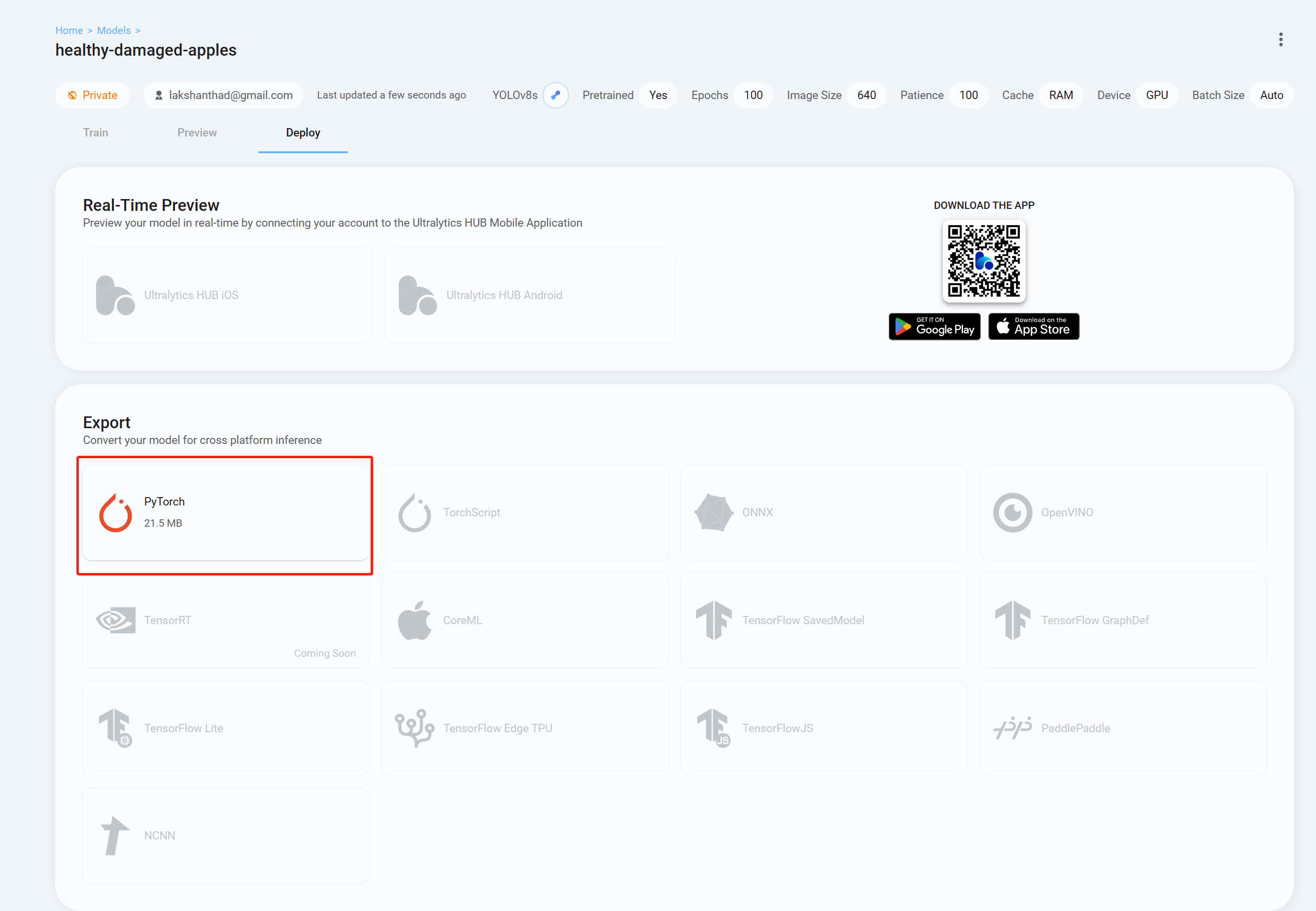
现在,您可以使用此下载的模型来执行我们之前在本 wiki 中解释过的任务。您只需要将模型文件替换为您的模型即可。
例如:
性能基准
准备
我们对 YOLOv8 支持的所有计算机视觉任务进行了性能基准测试,这些任务在由 NVIDIA Jetson Orin NX 16GB 模块提供支持的 reComputer J4012/reComputer Industrial J4012 上运行。
示例目录中包含一个名为trtexec的命令行包装工具。trtexec 是一个使用 TensorRT 的工具,无需开发自己的应用程序。trtexec 工具有三个主要用途:
- 根据随机或用户提供的输入数据对网络进行基准测试。
- 从模型生成序列化引擎。
- 从构建器生成序列化时序缓存。
这里我们可以使用trtexec工具来快速对不同参数的模型进行基准测试。但首先,你需要有一个onnx模型,我们可以使用ultralytics yolov8生成这个onnx模型。
- 步骤 1.
使用以下命令构建 ONNX:
- 步骤 2.
使用 trtexec 构建引擎文件,如下所示:
例如:
这将输出如下性能结果以及生成的 .engine 文件。默认情况下,它会将 ONNX 转换为 FP32 精度的 TensorRT 优化文件,您可以看到如下输出
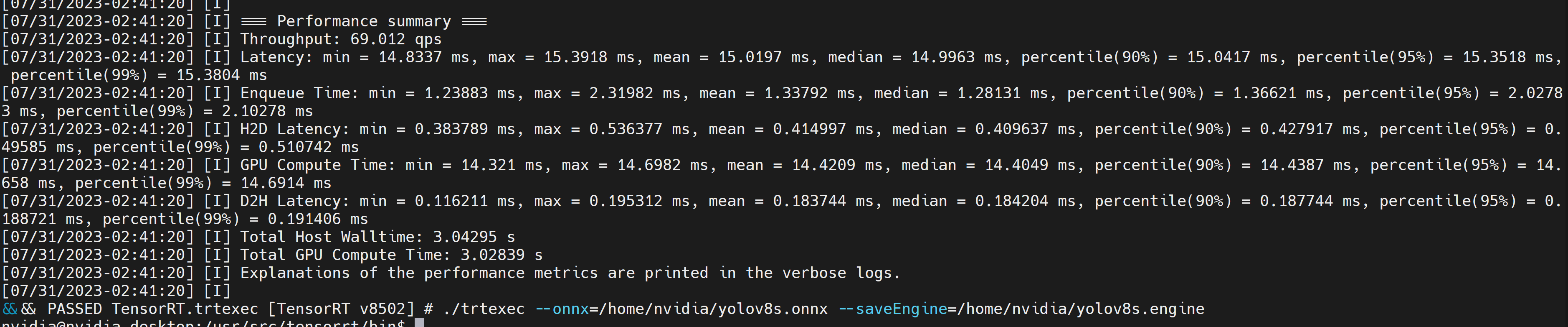
如果你想要FP16精度,比FP32提供更好的性能,你可以执行上面的命令,如下
但是,如果您希望INT8精度提供比FP16更好的性能,您可以执行上述命令,如下所示
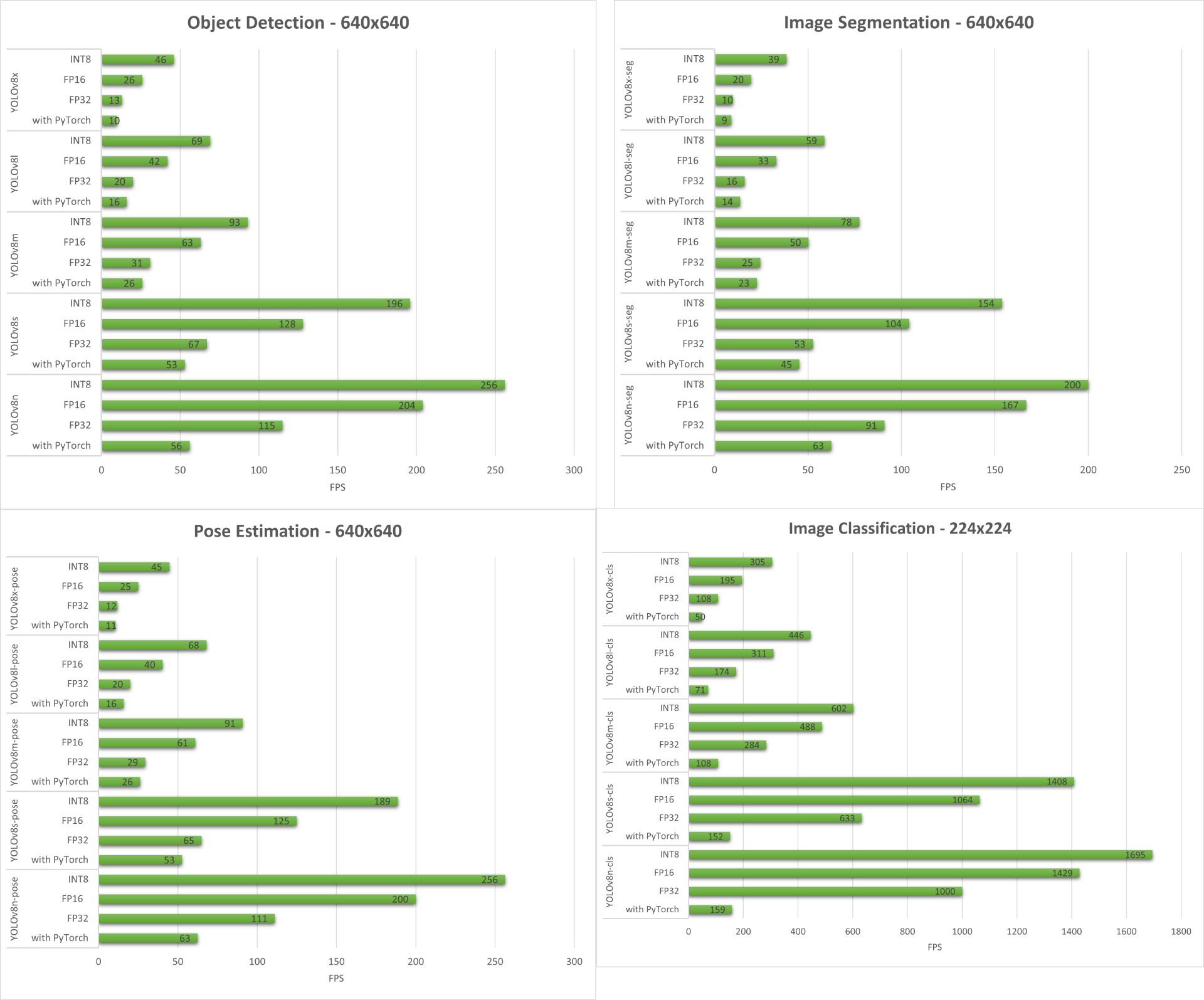
结果
下面我们总结了在 reComputer J4012/reComputer Industrial J4012 上运行的所有四个计算机视觉任务所获得的结果。
奖励演示:使用YOLOv8 的
我们使用 YOLOv8-Pose 模型构建了一个姿势估计演示应用程序,用于使用 YOLOv8 进行运动检测和计数。您可以在此处查看该项目以了解有关此演示的更多信息并在您自己的 Jetson 设备上进行部署!
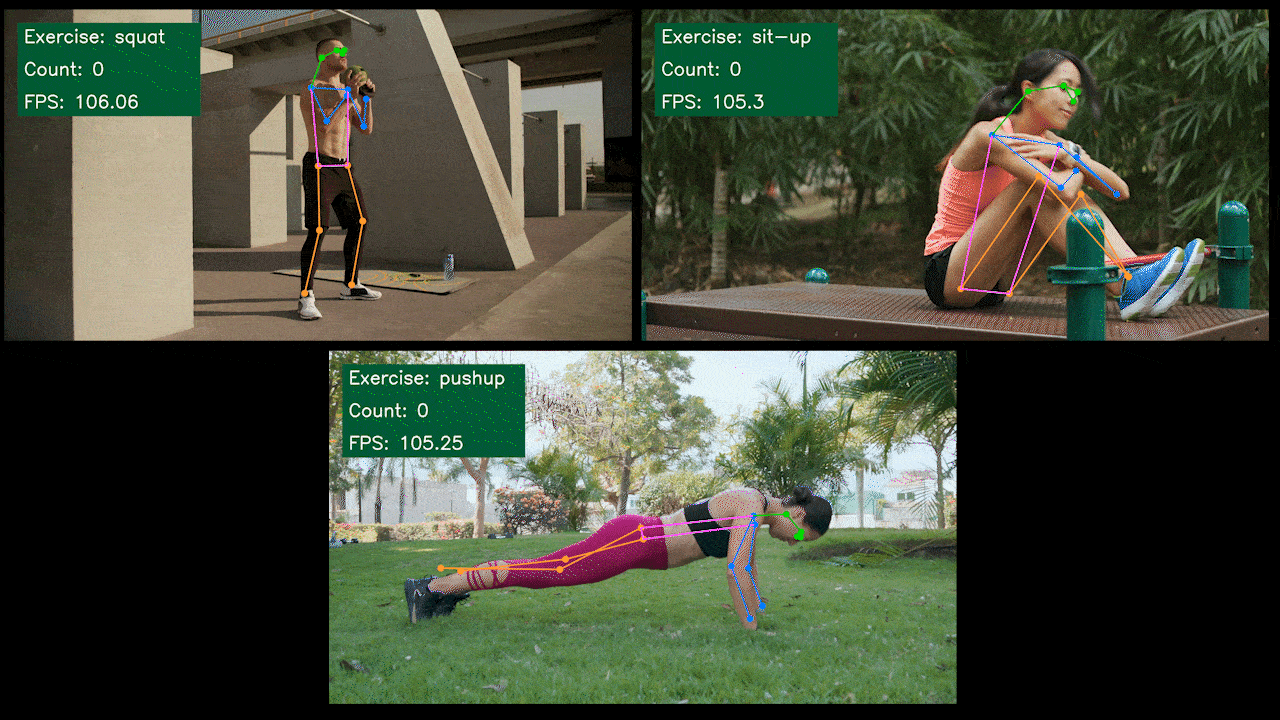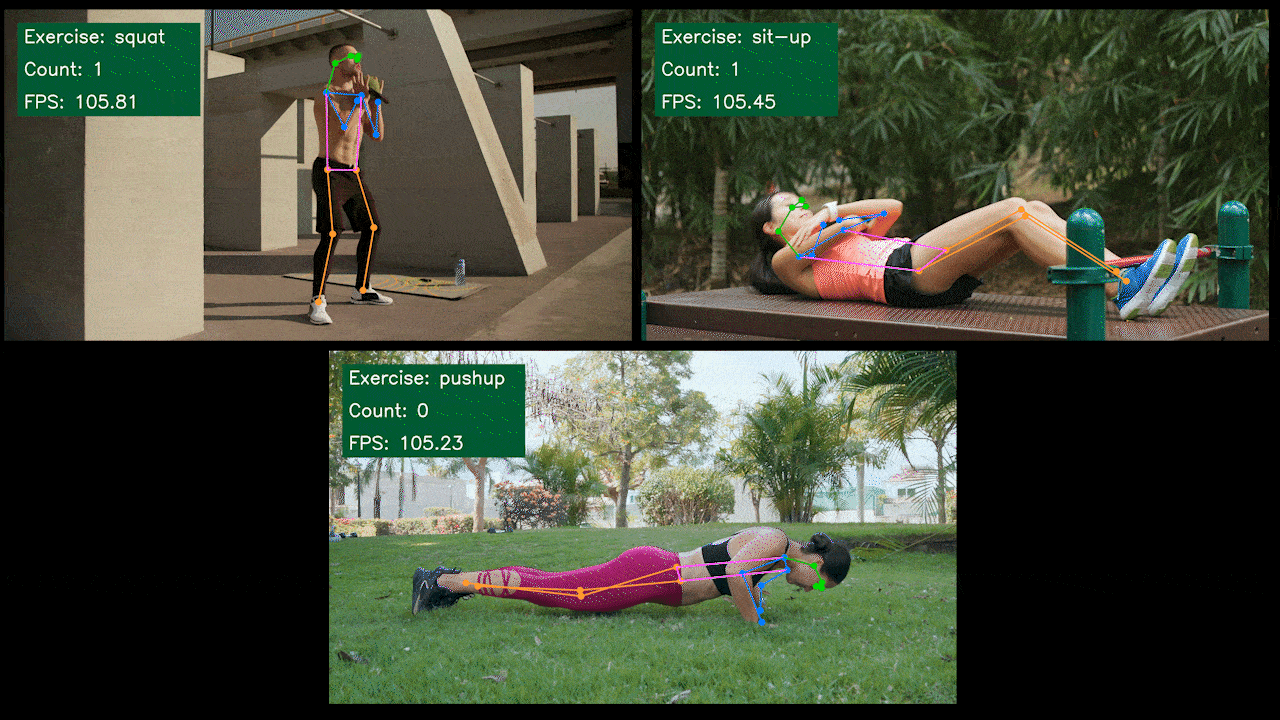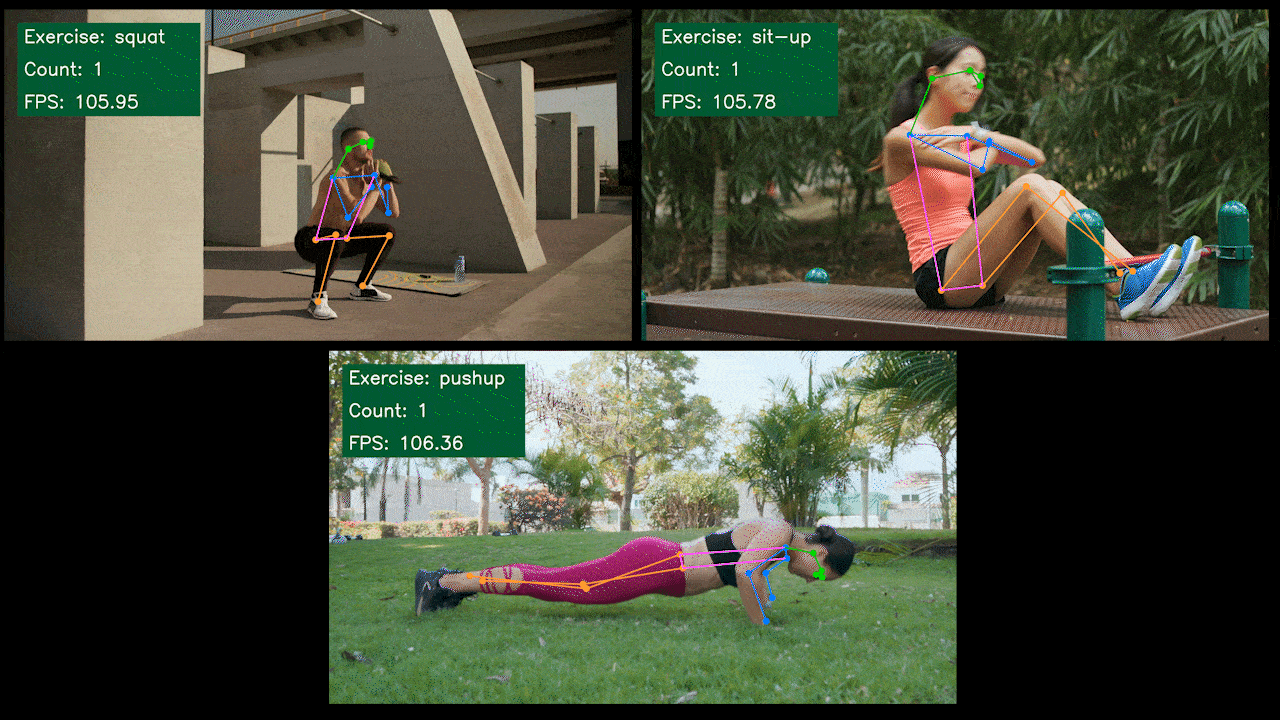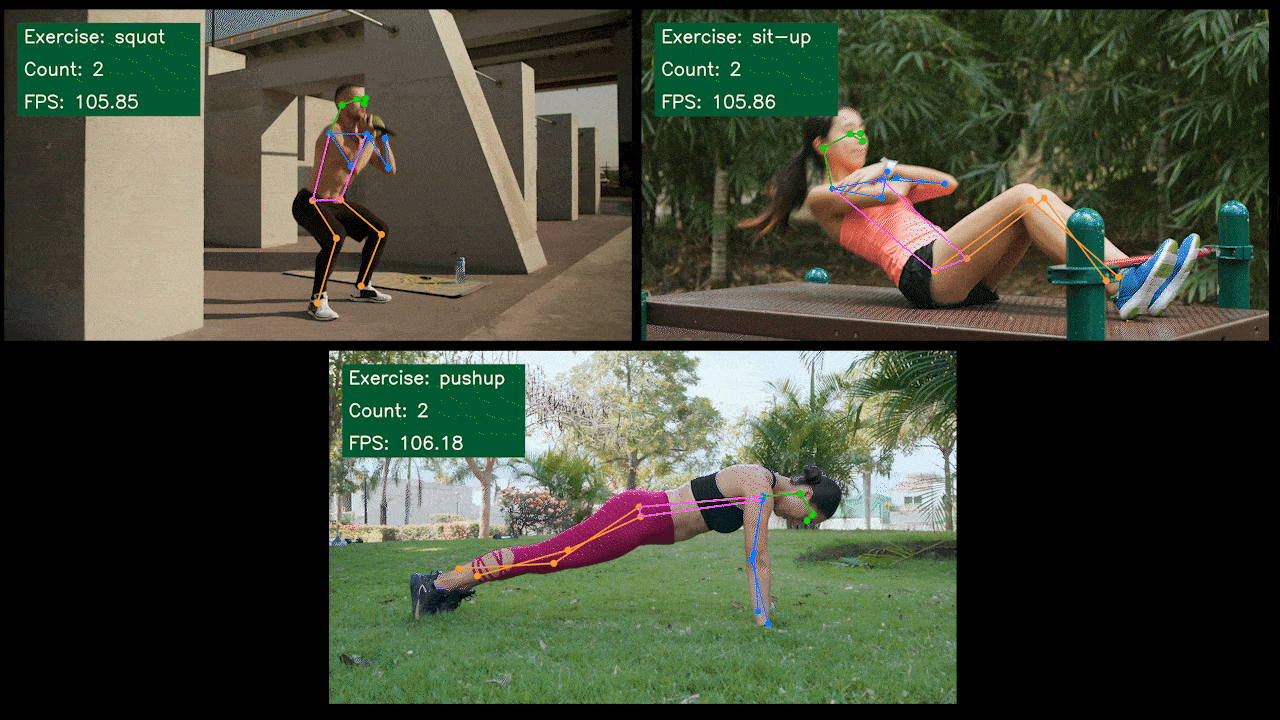
为 NVIDIA Jetson
如果我们之前提到的一行脚本有一些错误,您可以一一完成以下步骤,使用 YOLOv8 准备 Jetson 设备。
安装 Ultralytics软件包
- 步骤1.
访问Jetson设备的终端,安装pip并升级
- 步骤 2.
安装 Ultralytics 软件包
- 步骤 3.
将 numpy 版本升级到最新版本
- 步骤 4.
重新启动设备
卸载 Torch 和Torchvision
上述 ultralytics 安装将安装 Torch 和 Torchvision。然而,通过pip安装的这2个包不兼容在基于ARM aarch64架构的Jetson平台上运行。因此,我们需要手动安装预构建的 PyTorch pip Wheel 并从源代码编译/安装 Torchvision。
安装 PyTorch 和Torchvision
访问此页面可访问所有 PyTorch 和 Torchvision 链接。
以下是 JetPack 5.0 及以上版本支持的一些版本。
PyTorch v2.0.0
由带有 Python 3.8 的 JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) 支持
文件名: torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl URL: https: //nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl
PyTorch v1.13.0
由带有 Python 3.8 的 JetPack 5.0 (L4T R34.1) / JetPack 5.0.2 (L4T R35.1) / JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) 支持
文件名: torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl URL:https: //developer.download.nvidia.com/compute/redist/jp/v502/pytorch/torch-1.13.0a0 +d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl
- 步骤1.
根据您的JetPack版本安装torch,格式如下:pip3
例如,这里我们运行的是JP5.1.1,因此我们选择PyTorch v2.0.0
- 步骤 2.
根据您安装的 PyTorch 版本安装 torchvision。例如,我们选择PyTorch v2.0.0,这意味着我们需要选择Torchvision v0.15.2
以下是根据PyTorch版本需要安装的对应torchvision版本列表:
- PyTorch v2.0.0 - torchvision v0.15
- PyTorch v1.13.0 - torchvision v0.14
如果您想要更详细的列表,请查看此链接。
安装 ONNX 并降级Numpy
仅当您要将 PyTorch 模型转换为 TensorRT 时才需要此操作
- 步骤 1.
安装 ONNX,这是必需的
- 步骤 2.
降级到较低版本的 Numpy 以修复错误
pip3 install numpy==1.20.3- Author:zhuzi
- URL:/article/example-45
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!





